library(pwr)Power Analyses
Some Concepts to understand
Effect Size


Experiment 1 Measures the weights of swans and geese.
Experiment 2 Measures the weights of swans and robins.
What experiment is most likely to find a significant difference in weight between species?
Answer
Experiment 2 because the difference between swan and robin weight is bigger. The effect size is bigger.Sample Size (n)

Experiment 1 - Measures the heights of 10 female and 10 male giraffes.
Experiment 2 - Measures the heights of 100 female and 100 male giraffes.
What experiment is most likely to find a significant difference in height?
Answer
Experiment 2 because more of the population is sampled.
Significance (alpha) Level
All student projects in group A compare p values to an significance level of 0.05.
All student projects in group B compare p values to an significance level of 0.01.
What group are most likely to find a significant result?
Answer
Group A because the p values do not have to be as small to be below 0.05 and to reject the null hypothesis.
Type I Errors
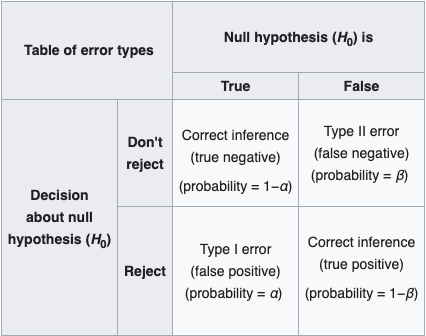
A type one error is when you find a significant result but in reality there is no significant effect or difference.
Example: a student project finds there is a difference in maths performance between girls and boys. But in reality this is unlikely to be the case since other researchers have not found this (Li et al., 2018, Lindberg et al., 2010, Reilly et al., 2019). The student would have made a type 1 error.
All student projects in group A compare p values to an alpha level of 0.05.
All student projects in group B compare p values to an alpha level of 0.01.
Which cohort is most likely to make type 1 errors in their projects?
Answer
Group A because the higher alpha level means they are more likely to reject the null hypothesis. They are therefore more likely to mistakenly reject a null hypothesis that in reality is true.
Type II Errors
A type two error is when you mistakenly accept the null hypothesis. You conclude there is no difference or effect when there really is.

Example: you measure the weights of male and female gorillas and find no significant difference. In reality males are a lot heavier. You would have made a type two error.
We want to reduce the risk of both type 1 and 2 errors. While it is debatable how to do this, there is a convention established that we use a significance level of 0.05 and 0.8 power.
Power
Power is the chance that a study will detect an effect if one exists.
A power analysis can tell us how many samples will give us 80% power (80% is 0.8 as a percentage).
In other words, you use an alpha level of 0.05, estimate your effect size, then choose a sample size that gives you 0.8 power.
A power analysis can also be used to determine how high the power of an analysis was that has already been done.
Power analyses in R
There are various packages which do power analysis in R. pwr is for simpler analyses such as t tests and ANOVAs, up to lm. simR and WebPower are for more complex mixed model glms.
First, download and install the package.
Power analyses to find out sample size
You want to know how many rats you should weigh, to detect an effect of a drug compared to a placebo where the effect size is 0.5, using a significance level of 0.05 and 0.8 power.
To do power calculations in pwr, you leave out sample size (n) but enter effect size (d), significance level and power:
pwr.t.test(n = NULL, d = 0.5, sig.level = 0.05, power = 0.8)
Two-sample t test power calculation
n = 63.76561
d = 0.5
sig.level = 0.05
power = 0.8
alternative = two.sided
NOTE: n is number in *each* groupWe need 128 rats.
Other Statistical Tests
The pwr package has a bunch of functions, but they all pretty much work the same way.
| Function | Description |
|---|---|
pwr.2p.test |
two proportions (equal n) |
pwr.2p2n.test |
two proportions (unequal n) |
pwr.anova.test |
balanced one way ANOVA |
pwr.chisq.test |
chi-square test |
pwr.f2.test |
general linear model |
pwr.p.test |
proportion (one sample) |
pwr.r.test |
correlation |
pwr.t.test |
t-tests (one sample, 2 sample, paired) |
pwr.t2n.test |
t-test (two samples with unequal n) |
Challenge
The function pwr.anova.test() performs a power analysis for a balanced anova (balanced is when all the groups have the same sample size). k is the number of groups to be compared and f is the effect size.
You are planning a project to measure the pollution concentration in fish from three lakes (three groups). Use an effect size of 0.2, significance level of 0.05 and power of 0.8. How many fish do you need to catch from each lake?

Answer
pwr.anova.test(f=0.2,k=3,power=0.80,sig.level=0.05)
Balanced one-way analysis of variance power calculation
k = 3
n = 81.29603
f = 0.2
sig.level = 0.05
power = 0.8
NOTE: n is number in each groupYou need to catch 81 fish from each lake, 243 in total.
Choosing an Effect Size Before the Experiment
If you really have nothing else to go on, assume an effect size of 0.5. However, you can normally do better than that, by looking at previous experiments you, or other people, have run.
Keep in mind that specifying effect size is not a statistical question, it’s an ecological question of what effect size is meaningful for your particular study? For example, do you want to be able to detect a 25% decline in the abundance of a rare animal or would you be happy detecting a 1% decline? For more explanation read the blog post The Effect Size: The Most difficult Step in Calculating Sample Size Estimates.
Power Analysis for Estimating Power
Imagine this experiment has already taken place. A new treatment was tested on 40 mice (20 in the control group and 20 in the treatment group) and measurements of success taken. The effect size was found to be 0.3.
Challenge
Use the function pwr.t.test and calculate what power the t test had. Use a significance level of 0.05.
Answer
pwr.t.test(n = 20, d = 0.3, sig.level = 0.05, power = NULL)
Two-sample t test power calculation
n = 20
d = 0.3
sig.level = 0.05
power = 0.1522683
alternative = two.sided
NOTE: n is number in *each* groupPower was only about 15%. This means that given the effect size, and sample size, we only detected that effect 15% of the time. So, it probably was not worth doing this experiment!
How big would the sample sizes in the experiment above have had to be to achieve 80% power? We can try n = 30:
pwr.t.test(n = 30, d = 0.3, sig.level = 0.05, power = NULL)
Two-sample t test power calculation
n = 30
d = 0.3
sig.level = 0.05
power = 0.2078518
alternative = two.sided
NOTE: n is number in *each* groupPower improves to around 20%. We need to try higher sample sizes. Instead of manually plugging in different values for n, we could make R run the power analysis for many different sample sizes. This code calculates and plots power for samples sizes from 2 to 200.
nvals <- seq(2, 200, length.out = 200)
powvals <- sapply(nvals, function(x) pwr.t.test(d = 0.3, n = x, sig.level = 0.05)$power)
plot(nvals, powvals,
xlab = "sample size", ylab = "power",
main = "Power curve for sample size for difference in proportions",
lwd = 2, col = "red", type = "l"
)
abline(h = 0.8)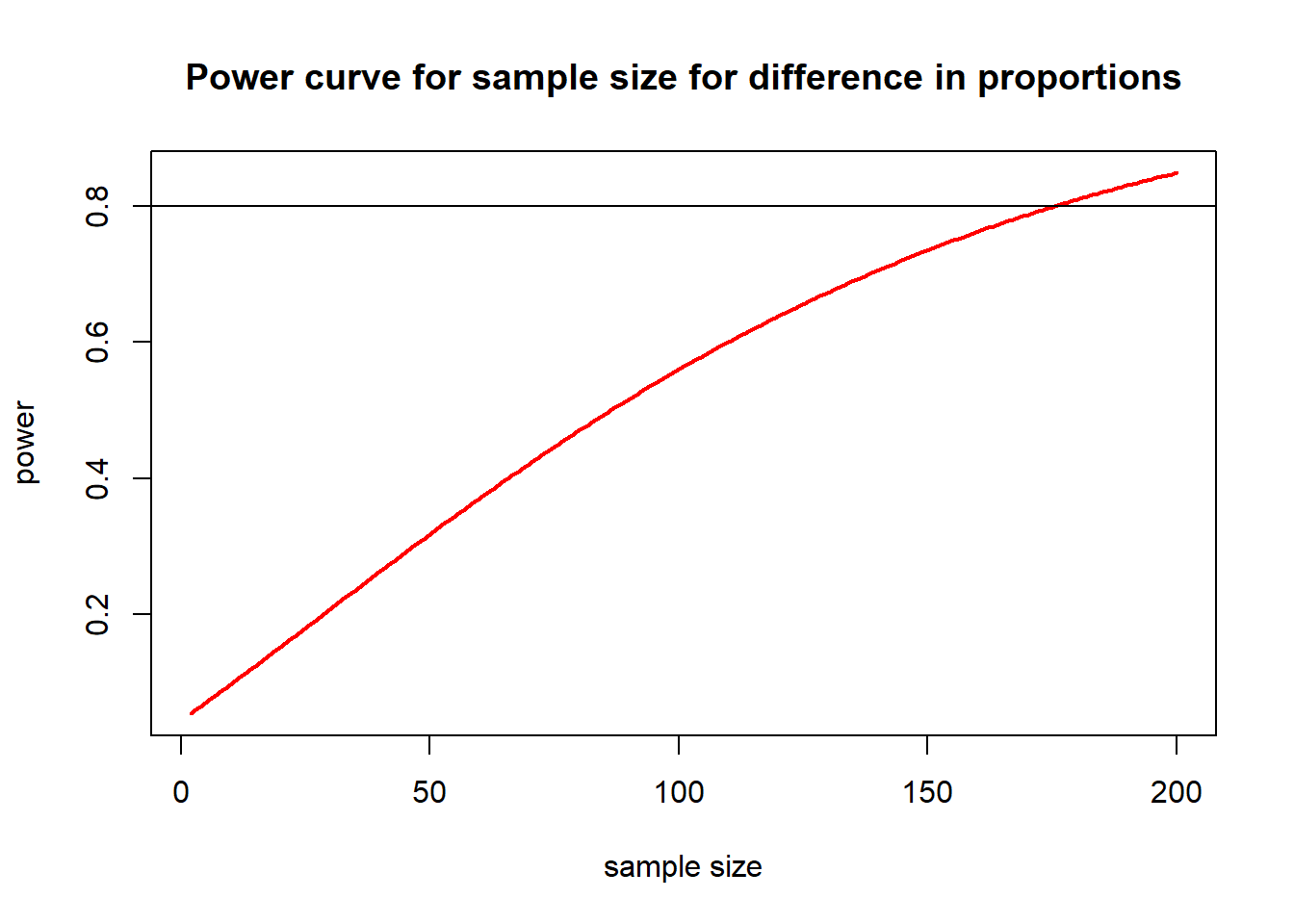
Explanation of code
nvals is an object made to store a sequence seq() of numbers from 2 to 200powvals is an object that will store the calculated powers retrieved using $powersapply() takes each number x in nvals and uses it in the function pwr.t.test()plot() graphs the numbers stored in nvals and powvals against each otherxlab, ylab and main are the x and y axes labels and main plot titlelwd is line width, col is line colour and type =1 is a solid lineabline() draws horizontal (h) line at 0.8
Now we can see that a sample size of around 175 for each group would have given enough power.
Run power analyses
Challenge
Calculate the power for the t test in this study.
Imagine you are planning to measure inhibitory control of zebra finches while in either a quiet environment or exposed to traffic noise. Decide how many birds you might have the resources to test and use that as n. Use a significance level of 0.05. Then estimate an effect size from the first paragraph of the Results section of Osbrink et al, 2021. Use these numbers to calculate what the power would be for a t test.
Would you change the number of birds that you initially thought you would test after doing a power analysis?

Hints
Before staring write down the number of birds in each group and in total you would plan to use.
Use the effect size d = 0.29 as reported in Osbrink et al, 2021.
Challenge

Calculate the power for the lm in the plant height study.
Plant_height <- read.csv(file = "data/Plant_height.csv", header = TRUE)
model <- lm(loght ~ temp, data = Plant_height)
summary(model)Hints
Choose an appropriate power function.
Make sure you are using the correct effect size.
Search the internet for functions that calculate effect size.
Challenge
Calculate the power for the binomial model in the crab study.
crabs <- read.csv("data/crabs.csv", header = T)
crabs$Time <- factor(crabs$Time)
crabs$Dist <- factor(crabs$Dist)
crab_glm <- glm(CrabPres ~ Time * Dist, family = "binomial", data = crabs)Hints
You will have to find out what power function is best for binomial regression (sometimes called logistic regression).
The effect size for a binomial regression is odds ratios. The coefficient given by R is the log odds.
There may be more than one log odds since there are two independent variables (Time and Distance) with multiple levels.
Adapted from Statistical Power by Andy Wills, Clare Walsh and Chris Longmore and EnvironmentalComputing.